The Reproducibility Project results have just been published in Science, a massive, collaborative, ‘Open Science’ attempt to replicate 100 psychology experiments published in leading psychology journals. The results are sure to be widely debated – the biggest result being that many published results were not replicated. There’s an article in the New York Times about the study here: Many Psychology Findings Not as Strong as Claimed, Study Says
This is a landmark in meta-science : researchers collaborating to inspect how psychological science is carried out, how reliable it is, and what that means for how we should change what we do in the future. But, it is also an illustration of the process of Open Science. All the materials from the project, including the raw data and analysis code, can be downloaded from the OSF webpage. That means that if you have a question about the results, you can check it for yourself. So, by way of example, here’s a quick analysis I ran this morning: does the number of citations of a paper predict how large the effect size will be of a replication in the Reproducibility Project? Answer: not so much
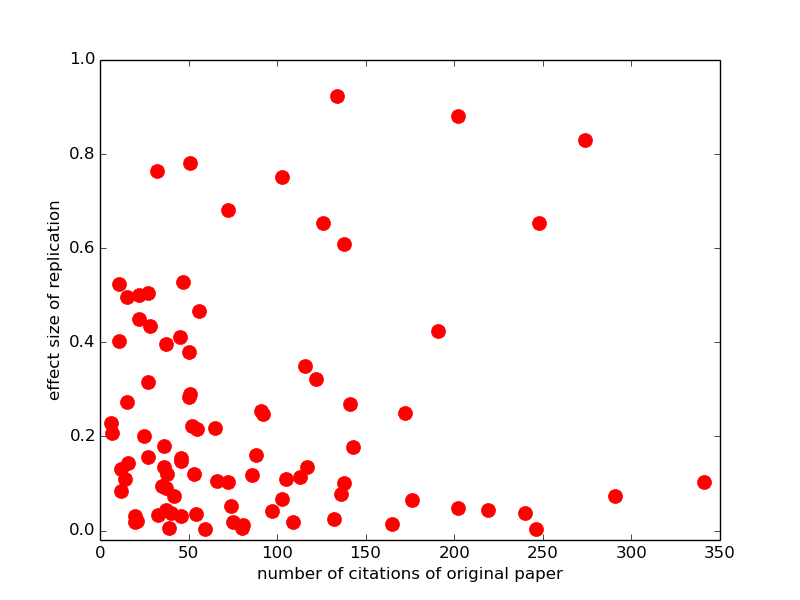
That horizontal string of dots along the bottom is replications with close to zero-effect size, and high citations for the original paper (nearly all of which reported non-zero and statistically significant effects). Draw your own conclusions!
Link: Reproducibility OSF project page
Link: my code for making this graph (in python)

This is a nice graph. But you should consider plotting citation counts on a log scale. In bibliometrics, relationships with citations counts are almost always best captured using a log scale. Plus, log-scale captures something meaningful about impact– a paper with 4 citations is quite a bit more cited than one with 1, but a paper with 104 citations is not meaningfully different in impact from one with 101.
It’s hard to eyeball, but there might be the ghost of a relationship in this data set once log scale is applied. It seems almost like there is a bifurcation of the highly cited–whereas the less impactful papers are all over the place in replication effect size, the highly cited seem to be either go big or go home…
Possible confounders? There could be highly cited papers which already reported small sample effect sizes, but had a large sample (hence, they are cited very often as example of high quality research?).