This piece is based on my talk to the UCL conference ‘The Role of Diagnosis in Clinical Psychology’. It was aimed at an audience of clinical psychologists but should be of interest more widely.
I’ve been a long–term critic of psychiatric diagnoses but I’ve become increasingly frustrated by the myths and over-generalisations that get repeated and recycled in the diagnosis debate.
So, in this post, I want to tackle some of these before going on to suggest how we can critique diagnosis more effectively. I’m going to be referencing the DSM-5 but the examples I mention apply more widely.
“There are no biological tests for psychiatric diagnoses”
“The failure of decades of basic science research to reveal any specific biological or psychological marker that identifies a psychiatric diagnosis is well recognised” wrote Sami Timini in the International Journal of Clinical and Health Psychology. “Scientists have not identified a biological cause of, or even a reliable biomarker for, any mental disorder” claimed Brett Deacon in Clinical Psychology Review. “Indeed”, he continued “not one biological test appears as a diagnostic criterion in the current DSM-IV-TR or in the proposed criteria sets for the forthcoming DSM-5”. Jay Watts writing in The Guardian states that “These categories cannot be verified with objective tests”.
Actually there are very few DSM diagnoses for which biological tests are entirely irrelevant. Most use medical tests for differential diagnosis (excluding other causes), some DSM diagnoses require them as one of a number of criteria, and a handful are entirely based on biological tests. You can see this for yourself if you take the radical scientific step of opening the DSM-5 and reading what it actually says.
There are some DSM diagnoses (the minority) for which biological tests are entirely irrelevant. Body dysmorphic disorder (p242), for example, a diagnosis that describes where people become overwhelmed with the idea that a part of their body is misshapen or unattractive, is purely based on reported experiences and behaviour. No other criteria are required or relevant.
For most common DSM diagnoses, biological tests are relevant but for the purpose of excluding other causes. For example, in many DSM diagnoses there is a general exclusion that the symptoms must be not attributable to the physiological effects of a substance or another medical condition (this appears in schizophrenia, OCD, generalized anxiety disorder and many many others). On occasion, very specific biological tests are mentioned. For example, to make a confident diagnosis of panic disorder (p208), the DSM-5 recommends testing serum calcium levels to exclude hyperparathyroidism – which can produce similar symptoms.
Additionally, there are a range of DSM diagnoses for which biomedical tests make up one or more of the formally listed criteria but aren’t essential to make the diagnosis. The DSM diagnosis of narcolepsy (p372) is one example, which has two such criteria: “Hypocretin deficiency, as measured by cerebrospinal fluid (CSF) hypocretin-1 immunoreactivity values of one-third or less of those obtained in healthy subjects using the same assay, or 110 pg/mL or less” and polysomnography showing REM sleep latency of 15 minutes or less. Several other diagnoses work along these lines – where a biomedical tests results are listed but are not necessary to make the diagnosis: the substance/medication-induced mental disorders, delirium, neuroleptic malignant syndrome, neurocognitive disorders, and so on.
There are also a range of DSM diagnoses that are not solely based on biomedical tests but for which positive test results are necessary for the diagnosis. Anorexia nervosa (p338) is the most obvious, which requires the person to have a BMI of less than 17, but this applies to various sleep disorders (e.g. REM sleep disorder which requires a positive polysomnography or actigraphy finding) and some disorders due to other medical conditions. For example, neurocognitive disorder due to prion disease (p634) requires a brain scan or blood test.
There are some DSM diagnoses which are based exclusively on biological test results. These are a number of sleep disorders (obstructive sleep apnea hypopnea, central sleep apnea and sleep-related hypoventilation, all diagnosed with polysomnography).
“Psychiatric diagnoses ‘label distress'”
The DSM, wrote Peter Kinderman and colleagues in Evidence-Based Mental Health is a “franchise for the classification and diagnosis of human distress”. The “ICD is based on exactly the same principles as the DSM” argued Lucy Johnstone, “Both systems are about describing people’s distress in terms of medical diagnosis”
In reality, some psychiatric diagnoses do classify distress, some don’t.
Here is a common criterion in many DSM diagnoses: “The symptoms cause clinical significant distress or impairment in social, occupational or other important areas of functioning”
The theory behind this is that some experiences or behaviours are not considered of medical interest unless they cause you problems, which is defined as distress or impairment. Note however, that it is one or the other. It is still possible to be diagnosed if you’re not distressed but still find these experiences or behaviours get in the way of everyday life.
However, there are a whole range of DSM diagnoses for which distress plays no part in making the diagnosis.
Here is a non-exhaustive list: Schizophrenia, Tic Disorders, Delusional Disorder, Developmental Coordination Disorder, Brief Psychotic Disorder, Schizophreniform Disorder, Manic Episode, Hypomanic Episode, Schizoid Personality Disorder, Antisocial Personality Disorder, and so on. There are many more.
Does the DSM ‘label distress’? Sometimes. Do all psychiatric diagnoses? No they don’t.
“Psychiatric diagnoses are not reliable”
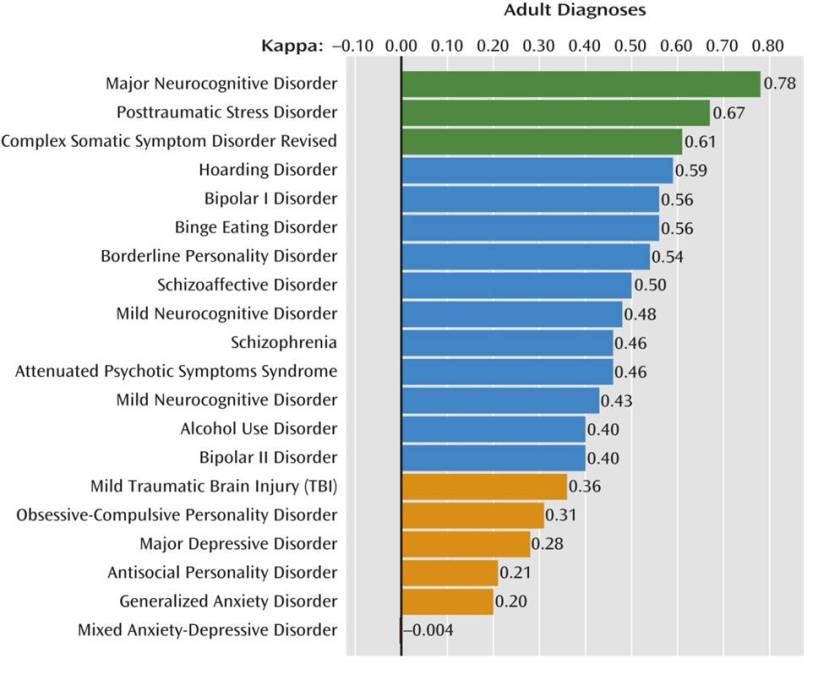
The graph below shows the inter-rater reliability results from the DSM-5 field trial study. They use a statistical test called Cohen’s Kappa to test how well two independent psychiatrists, assessing the same individual through an open interview, agree on a particular diagnosis. A score above 0.8 is usually considered gold standard, they rate anything above 0.6 in the acceptable range.
The results are atrocious. This graph is often touted as evidence that psychiatric diagnoses can’t be made reliably.
However, here are the results from a study that tested diagnostic agreement on a range of DSM-5 diagnoses when psychiatrists used a structured interview assessment. Look down the ‘κ’ column for the reliability results. Suddenly they are much better and are all within the acceptable to excellent range.
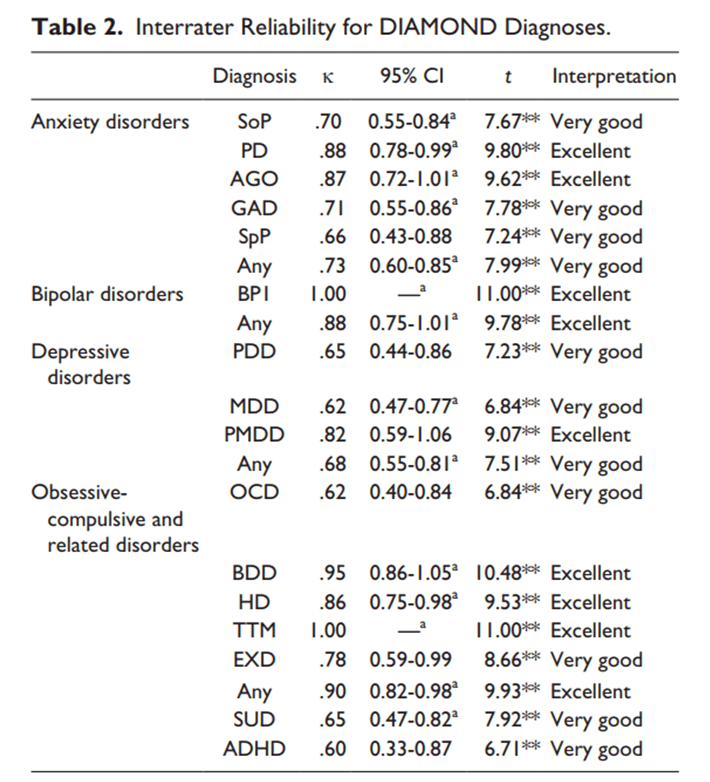
This is well-known in mental health and medicine as a whole. If you want consistency, you have to use a structured assessment method.
While we’re here, let’s tackle an implicit assumption that underlies many of these critiques: supposedly, psychiatric diagnoses are fuzzy and unreliable, whereas the rest of medicine makes cut-and-dry diagnoses based on unequivocal medical test results.
This is a myth based on ignorance about how medical diagnoses are made – almost all involve human judgement. Just look at the between-doctor agreement results for some diagnoses in the rest of medicine (which include the use of biomedical tests):
Diagnosis of infection at the site of surgery (0.44), features of spinal tumours (0.19 – 0.59), bone fractures in children (0.71), rectal bleeding (0.42), paediatric stroke (0.61), osteoarthritis in the hand (0.60 – 0.82). There are many more examples in the medical literature which you can see for yourself.
The reliability of DSM-5 diagnoses is typically poor for ‘off the top of the head’ diagnosis but this can be markedly improved by using a formal diagnostic assessment. This doesn’t seem to be any different from the rest of medicine.
“Psychiatric diagnoses are not valid because they are decided by a committee”
I’m sorry to break it to you, but all medical diagnoses are decided by committee.
These committees shift the boundaries, revise, reject and resurrect diagnoses across medicine. The European Society of Cardiology revise the diagnostic criteria for heart failure and related problems on a yearly basis. The International League Against Epilepsy revise their diagnoses of different epilepsies frequently – they just published their revised manual earlier this year. In 2014 they broadened the diagnostic criteria for epilepsy meaning more people are now classified as having epilepsy. Nothing changed in people’s brains, they just made a group decision.
In fact, if you look at the medical literature, it’s abuzz with committees deciding, revising and rejecting diagnostic criteria for medical problems across the board.
Humans are not cut-and-dry. Neither are most illnesses, diseases and injuries, and decisions about what a particular diagnosis should include is always a trade-off between measurement accuracy, suffering, outcome, and the potential benefits of intervention. This gets revised by a committee who examine the best evidence and come to a consensus on what should count as a medically-relevant problem.
These committees aren’t perfect. They sometimes suffer from fads and group think, and pharmaceutical industry conflicts of interest are a constant concern, but the fact that a committee decides a diagnosis does not make it invalid. I would argue that psychiatry is more prone to fads and pressure from pharmaceutical company interests than some other areas of medicine although it’s probably not the worst (surgery is notoriously bad in this regard). However, having a diagnosis decided by committee doesn’t make it invalid. Actually, on balance, it’s probably the least worst way of doing it.
“Psychiatric diagnoses are not valid because they’re based on experience, behaviour or value judgements”
We’ve discussed above how DSM diagnoses rely on medical tests to varying degrees. But the flip side of this, is that there are many non-psychiatric diagnoses which are also only based on classifying experience and/or behaviour. If you think this makes a diagnosis invalid or ‘not a real illness’ I look forward to your forthcoming campaigning to remove the diagnoses of tinnitus, sensory loss, many pain syndromes, headache, vertigo and the primary dystonias, for example.
To complicate things further, we know some diseases have a clear basis in terms of tissue damage but the diagnosis is purely based on experience and/or behaviour. The diagnosis of Parkinson’s disease, for example, is made this way and there are no biomedical tests that confirm the condition, despite the fact that studies have shown it occurs due to a breakdown of dopamine neurons in the nigrostriatal pathway of the brain.
At this point, someone usually says “but no one doubts that HIV or tuberculosis are diseases, whereas psychiatric diagnosis involves arbitrary decisions about what is considered pathological”. Cranks aside, the first part is true. It’s widely accepted – rightly so – that HIV and tuberculosis are diseases. However, it’s interesting how many critics of psychiatric diagnosis seem to have infectious diseases as their comparison for what constitutes a ‘genuine medical condition’ when infectious diseases are only a small minority of the diagnoses in medicine.
Even here though, subjectivity still plays a part. Rather than focusing on a single viral or bacterial infection, think of all viruses and bacteria. Now ask, which should be classified as diseases? This is not as cut-and-dry as you might think because humans are awash with viruses and bacteria, some helpful, some unhelpful, some irrelevant to our well-being. Ed Yong’s book I Contain Multitudes is brilliant on this if you want to know more about the massive complexity of our microbiome and how it relates to our well-being.
So the question for infectious disease experts is at what point does an unhelpful virus or bacteria become a disease? This involves making judgements about what should be considered a ‘negative effect’. Some are easy calls to make – mortality statistics are a fairly good yardstick. No one’s argued over the status of Ebola as a disease. But some cases are not so clear. In fact, the criteria for what constitutes a disease, formally discussed as how to classify the pathogenicity of microorganisms, can be found as a lively debate in the medical literature.
So all diagnoses in medicine involve a consensus judgement about what counts as ‘bad for us’. There is no biological test that which can answer this question in all cases. Value judgements are certainly more common in psychiatry than infectious diseases but probably less so than in plastic surgery, but no diagnosis is value-free.
“Psychiatric diagnosis isn’t valid because of the following reasons…”
Debating the validity of diagnoses is a good thing. In fact, it’s essential we do it. Lots of DSM diagnoses, as I’ve argued before, poorly predict outcome, and sometimes barely hang together conceptually. But there is no general criticism that applies to all psychiatric diagnoses. Rather than going through all the diagnoses in detail, look at the following list of DSM-5 diagnoses and ask yourself whether the same commonly made criticisms about ‘psychiatric diagnosis’ could be applied to them all:
Tourette’s syndrome, Insomnia, Erectile Disorder, Schizophrenia, Bipolar, Autism, Dyslexia, Stuttering, Enuerisis, Catatonia, PTSD, Pica, Sleep Apnea, Pyromania, Medication-Induced Acute Dystonia, Intermittent Explosive Disorder
Does psychiatric diagnosis medicalise distress arising from social hardship? Hard to see how this applies to stuttering and Tourette’s syndrome. Is psychiatric diagnosis used to oppress people who behave differently? If this applies to sleep apnea, I must have missed the protests. Does psychiatric diagnosis privilege biomedical explanations? I’m not sure this applies to PTSD.
There are many good critiques on the validity of specific psychiatric diagnoses, it’s impossible to see how they apply to all diagnoses.
How can we criticise psychiatric diagnosis better?
I want to make clear here that I’m not a ‘defender’ of psychiatric diagnosis. On a personal basis, I’m happy for people to use whatever framework they find useful to understand their own experiences. On a scientific basis, some diagnoses seem reasonable but many are a really poor guide to human nature and its challenges. For example, I would agree with other psychosis researchers that the days of schizophrenia being a useful diagnosis are numbered. By the way, this is not a particularly radical position – it has been one of the major pillars of the science of cognitive neuropsychiatry since it was founded.
However, I would like to think I am a defender of actually engaging with what you’re criticising. So here’s how I think we could move the diagnosis debate on.
Firstly, RTFM. Read the fucking manual. I’m sorry, but I’ve got no time for criticisms that can be refuted simply by looking at the thing you’re criticising. Saying there are no biological tests for DSM diagnoses is embarrassing when some are listed in the manual. Saying the DSM is about ‘labelling distress’ when many DSM diagnoses do not will get nothing more than an eye roll from me.
Secondly, we need be explicit about what we’re criticising. If someone is criticising ‘psychiatric diagnosis’ as a whole, they’re almost certainly talking nonsense because it’s a massively diverse field. Our criticisms about medicalisation, poor predictive validity and biomedical privilege may apply very well to schizophrenia, but they make little sense when we’re talking about sleep apnea or stuttering. Diagnosis can really only be coherently criticised on a case by case basis or where you have demonstrated that a particular group of diagnoses share particular characteristics – but you have to establish this first.
As an aside, restricting our criticisms to ‘functional psychiatric diagnosis’ will not suddenly make these arguments coherent. ‘Functional psychiatric diagnoses’ include Tourette’s syndrome, stuttering, dyslexia, erectile disorder, enuerisis, pica and insomnia to name but a few. Throwing them in front of the same critical cross-hairs as borderline personality disorder makes no sense. I did a whole talk on this if you want to check it out.
Thirdly, let’s stop pretending this isn’t about power and inter-professional rivalries. Many people have written very lucidly about how diagnosis is one of the supporting pillars in the power structure of psychiatry. This is true. The whole point of structural analysis is that concept, practice and power are intertwined. We criticise diagnosis, we are attacking the social power of psychiatry. This is not a reason to avoid it, and doesn’t mean this is the primary motivation, but we need to be aware of what we’re doing. Pretending we’re criticising diagnosis but not taking a swing at psychiatry is like calling someone ugly but saying it’s nothing against them personally. We should be working for a better and more equitable approach to mental health – and that includes respectful and conscious awareness of the wider implications of our actions.
Also, let’s not pretend psychology isn’t full of classifications. Just because they’re not published by the APA, doesn’t mean they’re any more valid or have the potential to be any more damaging (or indeed, the potential to be any more liberating). And if you are really against classifying experience and behaviour in any way, I recommend you stop using language, because it relies on exactly this.
Most importantly though, this really isn’t about us as professionals. The people most affected by these debates are ultimately people with mental health problems, often with the least power to make a difference to what’s happening. This needs to change and we need to respect and include a diversity of opinion and lived experience concerning the value of diagnosis. Some people say that having a psychiatric diagnosis is like someone holding their head below water, others say it’s the only thing that keeps their head above water. We need a system that supports everyone.
Finally, I think we’d be better off if we treated diagnoses more like tools, and less like ideologies. They may be more or less helpful in different situations, and at different times, and for different people, and we should strive to ensure a range of options are available to people who need them, both diagnostic and non-diagnostic. Each tested and refined with science, meaning, lived experience, and ethics.
 Dorothy Bishop has an excellent post
Dorothy Bishop has an excellent post  BBC World Service has an excellent radio
BBC World Service has an excellent radio 
 If you want a crystal clear introduction to the role genetics can play in human nature, you can’t do much better than an
If you want a crystal clear introduction to the role genetics can play in human nature, you can’t do much better than an